Dapper 分布式跟蹤系統 數據處理與存儲支持服務剖析
Dapper是谷歌開發的分布式跟蹤系統,旨在解決大規模分布式環境下服務調用鏈路的監控與性能分析難題。其核心價值在于能夠低開銷、透明化地收集、處理和存儲海量的跟蹤數據,為系統性能診斷、故障定位和架構優化提供數據支撐。本文將深入解析Dapper在數據處理與存儲層面的核心支持服務。
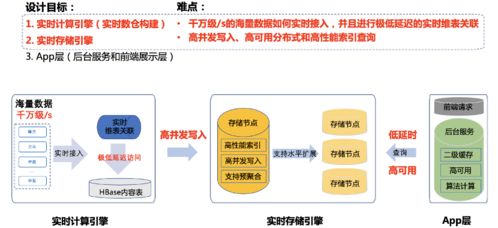
一、 數據處理流程:從采樣到聚合
Dapper的數據處理并非記錄每一次請求,而是通過采樣機制來控制數據量。其核心處理流程包括:
- 數據生成與收集:通過輕量級的代碼植入(如線程局部存儲),在服務調用的關鍵路徑(如RPC)自動生成跟蹤標識(TraceID、SpanID),并記錄時間戳、注解等元數據,形成原始的“Span”數據。
- 異步寫入與緩沖:生成的跟蹤數據首先被寫入本地日志文件或內存緩沖區。這種異步、批量寫入的方式對應用性能影響極低(低侵入性)。
- 數據匯聚與中轉:運行在每個機器上的Dapper守護進程定期收集本機的跟蹤日志,并將其批量發送到中央的收集器(Collector) 集群。
- 清洗與標準化:收集器對接收到的原始Span數據進行校驗、清洗,并將其轉換為標準化的格式,為后續存儲和索引做準備。
- 實時聚合與計算:部分關鍵指標(如錯誤率、延遲百分位數)會進行實時聚合計算,以支持監控儀表盤的快速展示。
二、 存儲支持服務:多級索引與海量持久化
Dapper的存儲設計需要應對每天數十億甚至百億級別的Span數據,其核心架構如下:
1. 核心存儲:BigTable
Dapper選擇谷歌的BigTable作為主存儲。其設計充分利用了BigTable的特性:
- 表結構設計:主要使用兩張表。
- Trace 表:以
TraceID作為行鍵,同一個Trace下的所有Span按時間順序存儲在同一行,便于高效重建完整調用鏈。
- 索引表:以
(服務名, 時間戳)等維度構建二級索引,支持按服務、時間范圍等條件快速查找相關的TraceID。
- 數據生命周期:原始跟蹤數據通常只保留有限時間(如幾天),而聚合后的關鍵指標和采樣后的“黃金信號”跟蹤會被保留更長時間,以平衡存儲成本與查詢需求。
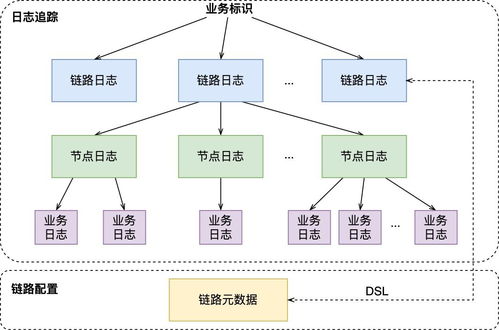
- 索引與查詢服務
- Dapper構建了專用的索引服務,持續消費收集器輸出的數據,為Trace數據建立多維索引(如服務、RPC方法、狀態碼、自定義注解等)。
- 面向用戶的 Dapper API 和 Web UI 提供查詢接口。用戶可以通過服務名、時間范圍、特定標簽甚至延遲閾值來搜索跟蹤記錄。查詢首先通過索引服務定位到TraceID,再從BigTable中讀取詳細的Span數據并組裝成完整的調用鏈樹進行可視化展示。
3. 數據聚合與歸檔
為了支持長期趨勢分析和離線數據挖掘,Dapper會將數據定期歸檔到谷歌的Colossus文件系統中,并可能使用MapReduce或Dataflow等批處理框架進行離線分析,生成服務依賴圖、性能基線報告等。
三、 核心設計思想與挑戰應對
- 低開銷與透明性:通過采樣和異步緩沖寫入,將性能影響控制在極低水平(如低于0.3%的延遲增加),使開發者無需修改業務代碼即可享受跟蹤能力。
- 可擴展性:收集器、存儲(BigTable)和索引服務均采用分布式集群設計,可以水平擴展以應對數據量的增長。
- 時效性與一致性的權衡:跟蹤數據追求近實時(分鐘級)可用即可,這降低了對強一致性的要求,允許系統采用更高效、最終一致的分布式處理管道。
- 應對“大尾巴”延遲:通過針對性采樣(如對慢請求進行更高概率采樣),確保能夠捕獲到那些對系統性能影響最大的罕見長尾請求,為性能優化提供關鍵線索。
結論
Dapper的成功不僅在于其精巧的跟蹤模型,更在于其背后強大、可擴展的數據處理與存儲支持服務。它構建了一個從數據生成、收集、清洗、索引到存儲查詢的完整管道,并巧妙地平衡了性能開銷、存儲成本、查詢效率與系統擴展性之間的關系。這一經典設計為后來眾多的開源分布式跟蹤系統(如Zipkin、Jaeger)提供了寶貴的藍本,奠定了現代可觀測性基礎設施的重要基石。
如若轉載,請注明出處:http://www.kvqb.cn/product/55.html
更新時間:2026-01-06 11:23:56