Hive數(shù)據(jù)倉庫 數(shù)據(jù)處理與存儲支持的強大服務
概述
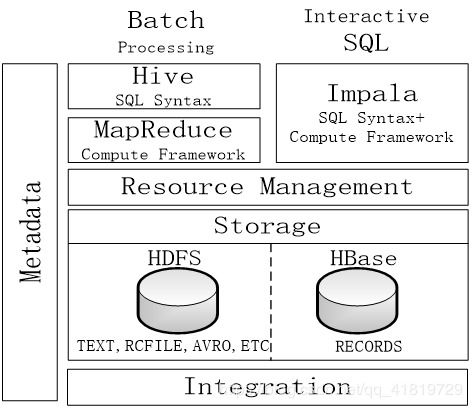
Hive是基于Hadoop構建的數(shù)據(jù)倉庫工具,旨在提供高效的數(shù)據(jù)處理與存儲支持服務。它將結構化的數(shù)據(jù)文件映射為數(shù)據(jù)庫表,并通過類SQL語言(HiveQL)進行查詢和分析,極大地降低了大數(shù)據(jù)處理的門檻,特別適用于數(shù)據(jù)倉庫、批量處理和即席查詢等場景。
數(shù)據(jù)處理支持
1. 數(shù)據(jù)查詢與分析
HiveQL支持豐富的查詢操作,包括SELECT、JOIN、GROUP BY等,并內(nèi)置大量聚合函數(shù)(如SUM、AVG、COUNT)和窗口函數(shù),便于復雜分析。通過將查詢轉(zhuǎn)換為MapReduce、Tez或Spark任務,Hive可高效處理PB級數(shù)據(jù),尤其適合批處理作業(yè)。
2. 數(shù)據(jù)轉(zhuǎn)換與清洗
Hive提供靈活的數(shù)據(jù)轉(zhuǎn)換功能。例如,可通過INSERT OVERWRITE或INSERT INTO語句將查詢結果寫入新表,實現(xiàn)數(shù)據(jù)清洗和聚合。支持自定義函數(shù)(UDF)和轉(zhuǎn)換腳本,滿足個性化處理需求,如日期格式化或文本解析。
3. 分區(qū)與分桶優(yōu)化
為提升查詢性能,Hive支持分區(qū)和分桶機制:
- 分區(qū):根據(jù)日期、地區(qū)等列將數(shù)據(jù)分割存儲,查詢時可跳過無關分區(qū),減少掃描數(shù)據(jù)量。
- 分桶:將數(shù)據(jù)哈希散列到固定數(shù)量的桶中,優(yōu)化JOIN和采樣操作,提升并行處理效率。
4. 復雜數(shù)據(jù)類型支持
除了基本類型,Hive還支持數(shù)組(ARRAY)、映射(MAP)和結構體(STRUCT)等復雜數(shù)據(jù)類型,便于處理嵌套或半結構化數(shù)據(jù)(如JSON日志),增強了數(shù)據(jù)建模的靈活性。
存儲支持服務
1. 多樣化存儲格式
Hive支持多種存儲格式,以適應不同場景:
- 文本格式(如CSV、JSON):易于閱讀和交換,但壓縮和查詢效率較低。
- 列式存儲格式(如ORC、Parquet):提供高壓縮比和列裁剪能力,顯著提升查詢性能,適合分析型負載。
2. 數(shù)據(jù)壓縮與優(yōu)化
Hive集成壓縮編解碼器(如Snappy、GZIP),減少存儲空間和I/O開銷。結合ORC或Parquet格式,可進一步優(yōu)化存儲效率,降低云存儲成本。
3. 元數(shù)據(jù)管理
Hive使用元數(shù)據(jù)存儲(如MySQL、PostgreSQL)管理表結構、分區(qū)信息和數(shù)據(jù)位置,確保數(shù)據(jù)一致性。元數(shù)據(jù)與HDFS等存儲系統(tǒng)解耦,便于多用戶協(xié)作和數(shù)據(jù)發(fā)現(xiàn)。
4. 集成與擴展性
Hive可與Hadoop生態(tài)系統(tǒng)無縫集成:
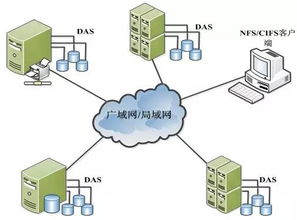
- 從HDFS、HBase或云存儲(如S3)讀取數(shù)據(jù)。
- 通過HiveServer2提供JDBC/ODBC接口,支持BI工具(如Tableau)直接連接。
- 結合Airflow等調(diào)度工具,構建自動化數(shù)據(jù)管道。
實際應用場景
- 數(shù)據(jù)倉庫構建:企業(yè)常使用Hive整合多源數(shù)據(jù)(如日志、事務記錄),構建中心化數(shù)據(jù)倉庫,支持歷史數(shù)據(jù)分析和報表生成。
- ETL處理:在數(shù)據(jù)湖中,Hive作為ETL引擎,清洗和轉(zhuǎn)換原始數(shù)據(jù),輸出結構化數(shù)據(jù)集供下游應用使用。
- 即席查詢:分析師通過HiveQL快速探索數(shù)據(jù),無需編寫復雜代碼,加速業(yè)務洞察。
##
Hive通過類SQL接口和分布式計算框架,提供了強大的數(shù)據(jù)處理與存儲支持服務。其分區(qū)、壓縮和列式存儲等優(yōu)化機制,兼顧了性能與成本,使其成為大數(shù)據(jù)生態(tài)中不可或缺的組件。盡管實時處理能力有限,但在批處理和數(shù)據(jù)分析領域,Hive依然發(fā)揮著關鍵作用,助力企業(yè)挖掘數(shù)據(jù)價值。
如若轉(zhuǎn)載,請注明出處:http://www.kvqb.cn/product/52.html
更新時間:2026-01-06 15:33:01